As we’ve been getting started on a Terracotta reference application, we’ve started thinking hard about the lifetime of every piece of data. And when we do that, it has become easier to decide where we store different kinds of data.
Some data needs to live effectively forever – that data is classic “system of record” stuff that is intrinsic to the business. For us, that means data like the users, the test definitions, and the results of taking those tests. That info goes in the database. And we use ORM to move between the app and the db as you’d expect.
Some data is short-term information used in the context of a single web or application request. That data obviously just stays in objects in memory and gets thrown away at the end of the request.
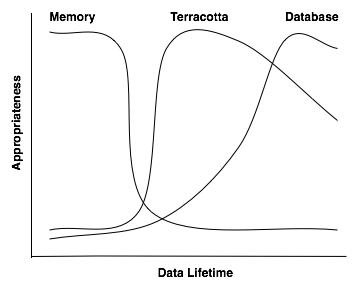
Thus, we’re handling the long-term and short-term data pretty much the same way you’d handle it without Terracotta. But in between those extremes is a middle gray area of data that needs to live “for a while” (longer than a single user-initiated request), but not forever where Terracotta is perfect. Some examples we’ve run across:
- Conversational data that serves as context over multiple requests from a user
- Complicated data that WILL be long-term but must be built in pieces
- Pending data that can be thrown away but only once another external action occurs
- Expiring data is a special case of pending data where the external action is timeout
During user registration, you collect some user information, then send a confirmation email with a code. The user data will be long-term and you can put that in the database. But the confirmation codes are pending data. They’re totally useless from a long-term point of view – they just need to stick around until a user confirms (via clicking a url or typing it into a web page).
For this kind of data where you need the availability and persistence of a database, but only need medium-term storage, Terracotta is a perfect match. You don’t need to map your data into tables, manage a schema, or do any of that. You simply store the data in a simple collection (Map, List, etc) and cluster that field with Terracotta. This gives you persistence (since the data is stored by the Terracotta server) and availability (since the data is available everywhere in the cluster).
This is just a little bit of data, of course, but once you starting looking for it, you see this temporary data everywhere. For example, when defining a new test, you need to build up a fair amount of data regarding test sections, questions, choices, etc. This is a good example of the complicated data item above.
One (of several) options you might consider would be using a series of pages to add information and saving each new or modified section, question, etc in the database as you go. If you do this, you need to come up with good ways to design your database tables and objects to cope with both changing test information as well as optimized reads for test taking. Those goals will conflict and you have to optimize for reads since other than test definition, all other uses are reads.
As an alternative, you can place that data in Terracotta where it is persistent and reliable and remains in object form while the test is being edited. At the point where the test is complete, you still save it to the database, doing whatever operations are necessary to optimize it for read access. This frees you from needing to think about the test editing use case from a persistent point of view. That makes development easier and the code simpler. And it offloads work from your (comparatively) expensive database.
The most obvious example of this is actually the only one we thought about initially – storing an “exam in progress” in Terracotta. The answers within a test are probably not particularly useful long-term. We only need to store the final grade, exam time, etc. So, during an exam, the user’s answers can be stored in Terracotta until the exam is complete or the exam period ends. At that point it can be scored and saved to the database as a result. This removes any need to store this information in the database, map it with ORM, etc and thus simplifies development. There are some interesting similarities to a cache with expiration although I think the intent is different.
Speaking of caching, a cache can be seen as nothing but an expiring middle-term copy of long-term data. That’s why Terracotta is so commonly used as a distributed data caching technology and why we integrate into many popular caching libraries. We will certainly be employing Terracotta in that role as well, but haven’t gotten to it yet.