In responding to a Terracotta forum question today, it struck me that we have a bunch of shared map and cache options at Terracotta and while the differences may be clear to us internally, they’re probably clear as mud outside our little shell.
Let’s start here with a picture:
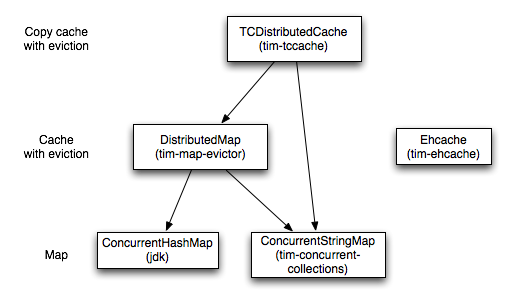
Maps
There are three levels here that build on each other. At the bottom layer we just have your standard ConcurrentMap implementations. At Terracotta, we have supported ConcurrentHashMap (CHM) for a long time. For an equally long time, we have had a special kind of map we used internally for our sessions product which we have finally pulled out and improved which is known as the ConcurrentStringMap (CSM).
Most Java developers are probably familiar with using CHM to safely use a shared map in a multi-threaded app. CHM is better than just a synchronized HashMap because it uses two levels of hashing internally. The first level of hash chooses an internal sub-map (known as a “segment”). Because the segments are independent, map callers can read or write to all internal segments in parallel, instead of the maximum of one allowing by a synchronized Map. Lock-striping for the win!
In a cluster, CHM helps. The Terracotta instrumented version of CHM actually takes things a bit further by using a read-write lock on every segment, allowing many readers even on the same segment. That, in combination with increasing the segment count from the default of 16 to 512 can usually do a pretty good job of improving concurrency.
However if you consider a cluster application where the app is partitioning data access across the nodes (by sticky session load balancer or other discriminating factor), then you run into the problem that you will still see collisions across nodes on all partitions. This is because the decision of how to map data to nodes and the decision of how to map keys to segments are different, meaning that the app locality is not preserved in your clustered data structure. Collisions are bad not just because they cause write contention, but because they force a distributed lock to move from one client to server array to another client. If locks can stay local, you don’t incur network overhead for locking.
In a single VM, this isn’t an issue but in the cluster it matters a lot. The ConcurrentStringMap provides one solution by effectively using N segments for N keys – every key has its own lock, which is itself the key (which must be a string). This guarantees that regardless of how you partition at the app level, the data structure is always perfectly partitionable. If your app is partitioned, locks can thus stay local all the time. This makes reads and writes blazingly fast while still giving you the same level of safety.
There is a downside to this approach, which is that you have drastically increased the number of objects by adding a lock per map entry. We’ve done some optimizations in 3.0 and some more in 3.0.1 that should help significantly with these issues and you should be fine with <8 million keys (per -Xmx2g node). Generally in our internal testing, we find that with a partitioned, multi-threaded, multi-node use case, the CSM completely destroys CHM by a wide margin on throughput (2-3x - depends heavily on the test of course). In our secret research labs, our very own mad scientist Chris “Hash This” Dennis (famous for the JavaPC project), has a prototype that uses a Bloom filter to allow only partial key sets to avoid keeping the entire key set in memory, thus allowing much larger maps while maintaining the majority of the performance. Still just a prototype but hopefully this will one day be another interesting alternative.
Caches and evictors
The structures above are maps – you put stuff in, you get stuff out. The second level in the picture are caches – you put stuff in but it might get old and thrown away before you can get it. For a long time we have supported Ehcache with a custom internal store and evictor. We significantly modify the data structure in ways that are somewhat similar to CHM – internal segements and locks. The evictor is optimized to avoid faulting unnecessarily during eviction.
During 2.7 we needed something like this for the Examinator reference app and built our own which resides in the tim-map-evictor project. The reason we built our own is that we are increasingly handcuffed by trying to optimize and simplify in terms of the Ehcache implementation. Writing our own allowed us to greatly simplify the internal store and evictor. As of 3.0, the tim-map-evictor store is based on CHM. In 3.1, we will provide the ability to use either CHM or CSM and CSM will probably become the default. We are also moving to greatly simplify the orphaned element eviction (elements no longer faulted into any node) by using our new 3.0 cluster events API.
Copy cache
We’ve also had some customers with a need to use a copy-cache. The caches we’ve mentioned till now are based on Terracotta shared object identity. That means that when you put an object in the cache, someone else on another node gets the same object with the same object identity. Nothing is ever copied or serialized in ways many clustered caches need to do such that you can end up with two versions of an object representing the same entity. This is great for many use cases but introduces the constraint that if you mutate one of those shared objects, you must obtain a clustered lock (as the node “over there” has the same object and will see the updates).
In some cases, you don’t care about that and want to lose object identity. In that case, you can use the tccache, which actually serializes keys and values on put and get from the cache. Doing the serialization obviously adds latency – we are still experimenting with a bunch of tricks to minimize that. On the positive side, there are some differences in usability as none of the classes being added to the cache need clustered instrumentation or locking. There’s a possibility down the line that you might not even need a boot jar to use tc cache and that might make tccache a really compelling alternative to something like memcache.
Hibernate 2nd level cache
This is not directly related, but I would be remiss not to mention here that in Terracotta 3.1 we are building a new Terracotta clustered Hibernate second level cache. This cache will support read, read-write, and transactional cache levels and read-committed and read-repeated isolation levels in the transactional cache. It will work in both Hibernate 3.2 and 3.3. We are utilizing the CSM and map-evictor technology from above in building this cache, along with some custom tweaks just for Hibernate cache.
We do have a small alpha program running. If you have an existing Hibernate 2nd level cache, particularly if you are using read-write or transactional cache concurrency strategies, and you’d be willing to give us some feedback on how your app performs with it, we’d love to talk to you. Drop me a line at amiller at terracotta dot org.