Brian’s talk focused pretty much exclusively on the new fork-join framework that will be added as part of the JSR 166 extension in Java 7. There are a few other little goodies in the JSR update but this is the big one.
He started with an overview of how times have changed since the initial JSR 166 release in Java 5. At that time, the focus was on providing tools and utilities to help write concurrent programs on boxes with a small number of cores as that was becoming prevalent.
Brian showed a graph from Herb Sutter’s article “The Free Lunch is Over” of the clock speed and transistor count of Intel chips over time.
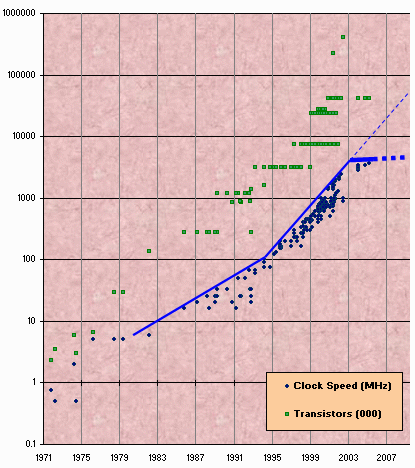
As you can see, CPU speeds stopped increasing around 2003 although transistor counts per chip continue to follow the trend. Clearly the trend is for an increasing number of cores, not increasing single core speed. The tools we have in Java 5 are good enough to find coarse-grained parallelism (usually at the unit of a user request) and spread it over a small number of cores (2-8). However, these tools do not scale up to many-core boxes, which will become increasingly prevalent. The shared queues and other infrastructure used by executors and thread pools becomes a point of contention and reduce scalability.
The fork-join framework is designed to address exactly the kind of fine-grained parallelism that will be needed to keep all your cores cranking away on CPU-intensive tasks. If you aren’t doing that, you’re wasting cycles. Fork-join is a divide-and-conquer style framework that is easy to execute and provides for a high degree of fine-grained parallelism.
The ForkJoinExecutor allows you to submit a task for processing. Each task is broken (recursively) into smaller pieces until some minimum threshold is reached at which point processing occurs. Each task must know how to break itself up.
The act of doing the task splitting is actually fairly boilerplate for many common cases, so they created a framework for this that looks like a functional API. You start with some kind of Parallel*Array object and then can apply filters, mappings, aggregation, etc to it. Under the hood everything is done with fork-join. If we get closures in Java 7, then that dramatically simplifies the API.
Fork-join is actually implemented using an idea called “work-stealing”. Basically, every thread has its own dequeue (double-ended queue, pronounced “deck”) and only that thread reads from the head of the queue. If a thread runs out of work, it steals work from the tail of someone else’s queue. Because the initial biggest jobs are placed at the tail of each queue, workers steal the biggest task available, which keeps them busy for longer. This further reduces queue contention and also provides built-in load balancing.
Brian also showed some performance calculations on varying #s of cores and varying sequential thresholds. In particular, he showed very good speed up with a sweet spot threshold (15x improvement on 32 cores) but also showed that even if you guess really wrong, you still get ok results.
I used fork-join back when I did my Mandelbrot presentation last fall and thought it was pretty cool. I was not aware at the time of the Parallel stuff as the docs were really hard to understand or missing. I’m looking forward to seeing Brian’s slides once they’re released to see how I could have better written the Mandelbrot program.
It’s nice to see that this library doesn’t depend on Java 7 either – you can get it and use it now, so we don’t have to wait till Java 7, whatever decade that arrives in.